公司的HBase集群偶尔有个很奇怪的现象:内存占用会逐渐升高,超过堆内堆外内存限制,直到把操作系统内存占满被oom-killer杀死。在内存占用逐步升高的期间,响应延迟越来越高,最终服务宕机也会造成集群抖动,影响SLA。
内存增长过程非常缓慢,大概一两个月宕机一次。之前一直苦恼于没有现场,这次终于抓到了一个稳定复现的集群。
目前还没正式修复,修复验证也要几周时间,所以等我验证后再补充效果。
现象
用户反馈集群的延迟远高于其他集群,之前SRE进行过扩容也没有效果,所以开发介入开始排查。
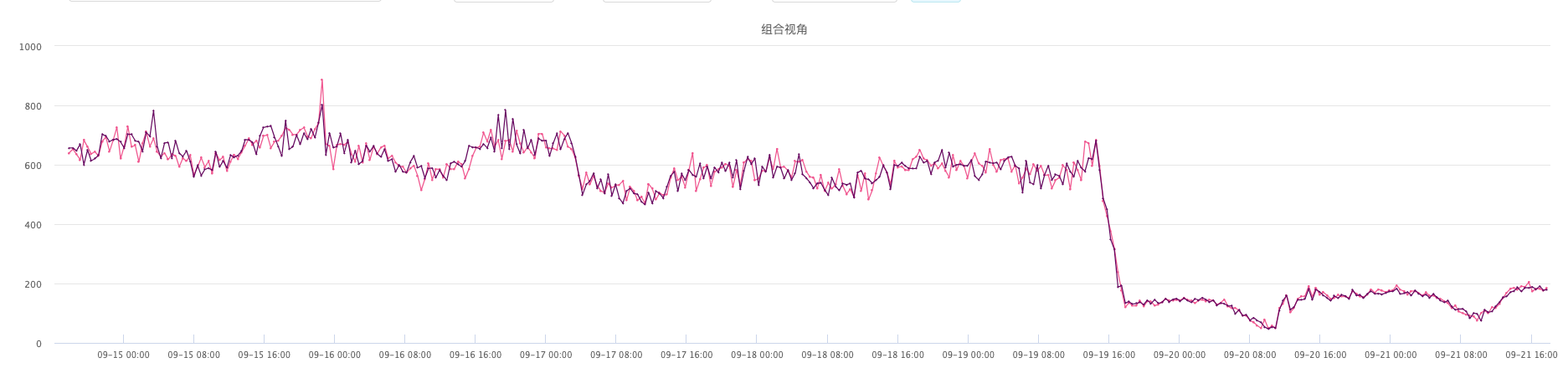
查看集群监控,发现两台节点的内存占用非常高,接近100%。随后就会被oom-killer杀掉。
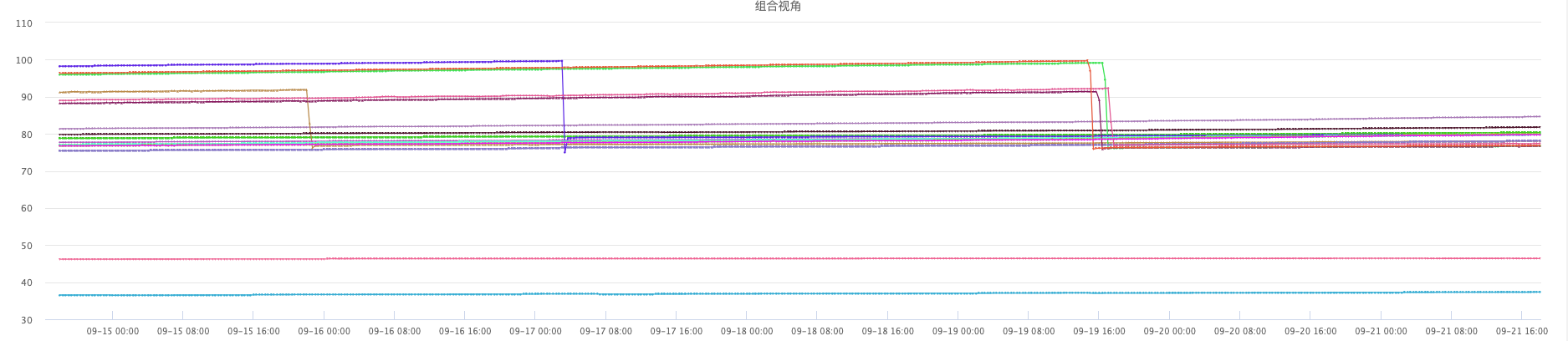
我们线上机器128G内存,这个集群HBase配置堆内40G堆外50G,加上其他进程的内存使用,整体内存使用率在80%算是比较合理的。
内存占用高之后,操作系统没有可用内存,会频繁的进行内存回收,如果回收速度跟不上,还会由后台回收变为直接回收,暂停进程的内存申请。在Java进程里也会看到莫名的GC。
可以用sar -B查看内存回收情况。忘记现场留图了,之后有图再补。
现场处理
开始排查时还有两个节点内存异常,请求慢日志数量明显高于其他节点。
用top查看内存使用,RegionServer进程占用在113G左右,远超限制,可以确定是发生内存泄漏了。
其中一台已经没法用arthas进行挂载了,只能先重启。
剩余一台赶紧用arthas挂进去看,发现堆内堆外大小都正常,但metaspace达到12G。当时也没有截图,这里用目前线上的一台机器示意一下:
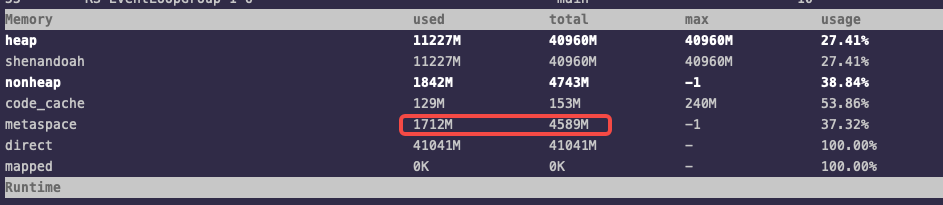
补图,某个节点的metaspace逐渐增长到11G:

这时候猜测是JVM的metaspace发生了内存泄漏,因为metaspace没有大小限制,会一直向操作系统申请内存,直至把内存占满。
赶紧打个heap dump好慢慢查。因为打dump会Full GC,发生长时间的STW,大内存的RS会因为和ZK失联宕机,所以一般线上不轻易打dump。
在我重启了两台节点之后,用户侧的延迟就明显下降了
排查
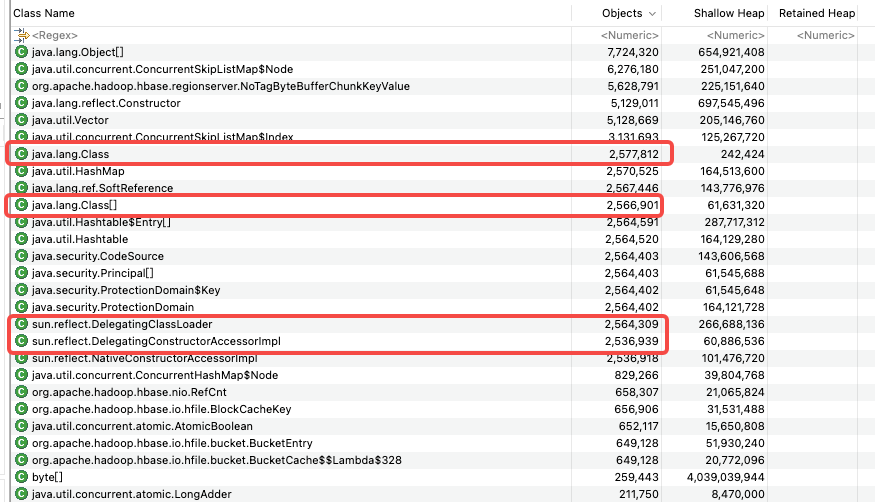
把heap dump下载到本地之后,用MAT打开。好家伙250多万的Class,这时候可以确定是metaspace出问题了。
这里还有个插曲,在用MAT打开的时候,一直卡在分析unreachable objects的这一步。这个dump只有8G,之前分析30G的dump都没卡住,查了一下把这一步跳过就顺利打开了。
直接通过MAT查看Class的引用关系,并看不出是怎么产生的。后面的DelegatingClassLoader的异常,也是后来发现的,当时没注意到。
网上一通查,找到从一起GC血案谈到反射原理,按步骤可以完整复现。
用sa-jni.jar dump出GeneratedMethodAccessor的字节码:
20: aaload
21: checkcast #14 // class "[B"
24: invokestatic #10 // Method org/apache/hadoop/hbase/filter/FirstKeyOnlyFilter.parseFrom:([B)Lorg/apache/hadoop/hbase/filter/FirstKeyOnlyFilter;
27: areturn
看24这行,这里显示是在执行org.apache.hadoop.hbase.filter.FirstKeyOnlyFilter.parseFrom()方法,这是HBase的Filter功能相关的类。那就直接去找代码,看什么地方会用反射处理Filter的逻辑。
/**
* Convert a protocol buffer Filter to a client Filter
*
* @param proto the protocol buffer Filter to convert
* @return the converted Filter
*/
@SuppressWarnings("unchecked")
public static Filter toFilter(FilterProtos.Filter proto) throws IOException {
String type = proto.getName();
final byte [] value = proto.getSerializedFilter().toByteArray();
String funcName = "parseFrom";
try {
Class<?> c = Class.forName(type, true, ClassLoaderHolder.CLASS_LOADER);
Method parseFrom = c.getMethod(funcName, byte[].class);
if (parseFrom == null) {
throw new IOException("Unable to locate function: " + funcName + " in type: " + type);
}
return (Filter)parseFrom.invoke(c, value);
} catch (Exception e) {
// Either we couldn't instantiate the method object, or "parseFrom" failed.
// In either case, let's not retry.
throw new DoNotRetryIOException(e);
}
}
找到唯一一处:RS从client发来的请求中,用反射的方式解析出Filter。那八成就是这个地方有问题了。
因为这个字节码只能从运行中的进程中去抓,所以分析dump的进程和抓这个
GeneratedMethodAccessor字节码的进程不是同一个,虽然它的GeneratedMethodAccessor数量也明显异常,并且绝大多数都和Filter有关,但不能百分百联系起来,后面我会再抓一次现场确认。
原因
补充个背景,这个集群使用的是ShenandoahGC,是公司内自己编译的包含SGC的JDK8,并不是社区的发行版。之前也出现过兼容问题导致出core dump。而且加了-XX:+ShenandoahAlwaysClearSoftRefs配置,不管其他配置,直接清理软连接。
Unconditionally clear soft references, instead of using any
other cleanup policy. This minimizes footprint at expense of
more soft reference churn in applications.
然后参考从一起GC血案谈到反射原理梳理下原因:
- Java
Class里的reflectionData是用SoftReference修饰的,会在GC时回收,而因为有-XX:+ShenandoahAlwaysClearSoftRefs配置,回收软连接会更激进 - 在通过
Class获取Method时,可能会因为reflectionData被回收,而需要重新copy产生一个新的Method - 在
Method.invoke的时候,会通过methodAccessor去执行。因为Method是copy产生的新对象,所以methodAccessor也是新对象。 methodAccessor的实现是DelegatingMethodAccessorImpl,这是个包装类,具体逻辑会委派给NativeMethodAccessorImpl和GeneratedMethodAccessorXXX,后面XXX是递增的数字。DelegatingMethodAccessorImpl的前15次执行是NativeMethodAccessorImpl处理,超出后产生一个GeneratedMethodAccessorXXX类进行处理,而这些对于JVM来说是不同的类,即都需要在metaspace里存储自己的元信息。这就是GeneratedMethodAccessorXXX和Class泛滥的原因- 而每个
GeneratedMethodAccessorXXX都有个单独的ClassLoader,就是DelegatingClassLoader,这就是DelegatingClassLoader也有250多万个的原因
目前不明确的问题还有为什么GeneratedMethodAccessor和DelegatingClassLoader不会被回收,我理解在metaspace不断扩大的过程中,应该是会触发回收的。不知道是不是和SGC有关。
模拟复现
复现的基本思路:
- 模拟Filter触发反射
- 使用类似的GC和JVM参数
- 监控一段时间的metaspace变化
代码模拟
写个demo模拟HBase高并发的情况下处理Filter:
public class MemLeakFilter {
// 构造一些不同的filter
private final List<Supplier<Filter>> suppliers = Lists.newArrayList(
FirstKeyOnlyFilter::new,
() -> new ColumnCountGetFilter(3),
() -> new ColumnPrefixFilter("prefix".getBytes()),
() -> new ColumnRangeFilter("start".getBytes(), true, "end".getBytes(), true),
() -> new ColumnValueFilter("family".getBytes(), "qualifier".getBytes(), CompareOperator.EQUAL, "value".getBytes())
);
public static void main(String[] args) throws Exception {
new MemLeakFilter().run();
}
private void run() {
// 64线程并发执行
ExecutorService es = Executors.newFixedThreadPool(64);
for (int i = 0; i < 64; i++) {
Supplier<Filter> supplier = suppliers.get(i % suppliers.size());
es.submit(() -> runOnce(supplier));
}
}
private void runOnce(Supplier<Filter> supplier) {
int cnt = 0;
while (true) {
try {
if (++ cnt == 100000) {
cnt = 0;
Thread.sleep(10);
}
// 构造一些大对象,尽量频繁触发GC
byte[] data = new byte[1024];
Arrays.fill(data, (byte) 1);
// 触发filter的序列化和反序列化,ProtobufUtil.toFilter中会执行反射的逻辑
ProtobufUtil.toFilter(ProtobufUtil.toFilter(supplier.get()));
} catch (Exception e) {
log.warn("filter exception", e);
}
}
}
}
执行demo
参考线上JVM配置,执行demo程序:
- 内存设置,堆内外都是1G
- 使用SGC,并开启
-XX:+ShenandoahAlwaysClearSoftRefs
/opt/soft/j2sdk-image/bin/java \
-XX:+UnlockExperimentalVMOptions \
-verbosegc \
-XX:+PrintGCApplicationStoppedTime \
-Xmx1g -Xms1g -XX:MaxDirectMemorySize=1g -Xss256k \
-XX:+PrintTenuringDistribution \
-XX:PrintFLSStatistics=1 \
-XX:+DisableExplicitGC \
-XX:+UseShenandoahGC \
-XX:ShenandoahAllocationThreshold=5 \
-XX:ShenandoahRefProcFrequency=3 \
-XX:+ShenandoahAlwaysClearSoftRefs \
-XX:ShenandoahGCHeuristics=compact \
-XX:ConcGCThreads=8 -XX:ParallelGCThreads=12 \
-XX:+UseBiasedLocking \
-XX:NumberOfGCLogFiles=100 -XX:+UseGCLogFileRotation -XX:GCLogFileSize=128m \
-XX:+PrintHeapAtGC \
-XX:+PrintGCDateStamps \
-XX:+UseNUMA \
-XX:+PrintSafepointStatistics \
-XX:+SafepointTimeout \
-XX:+PrintAdaptiveSizePolicy \
-XX:+PrintGC -XX:+PrintGCDetails \
-XX:+AlwaysPreTouch \
-XX:PrintSafepointStatisticsCount=1 \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/home/work/test \
-jar demo.jar
监控metaspace
demo程序启动后,使用jstat一直监控进程内存的变化
jstat -gc <pid> 10000
从9.26号收集到10.7号,10s一个点,metaspace的MC从32M逐渐增长到128M。
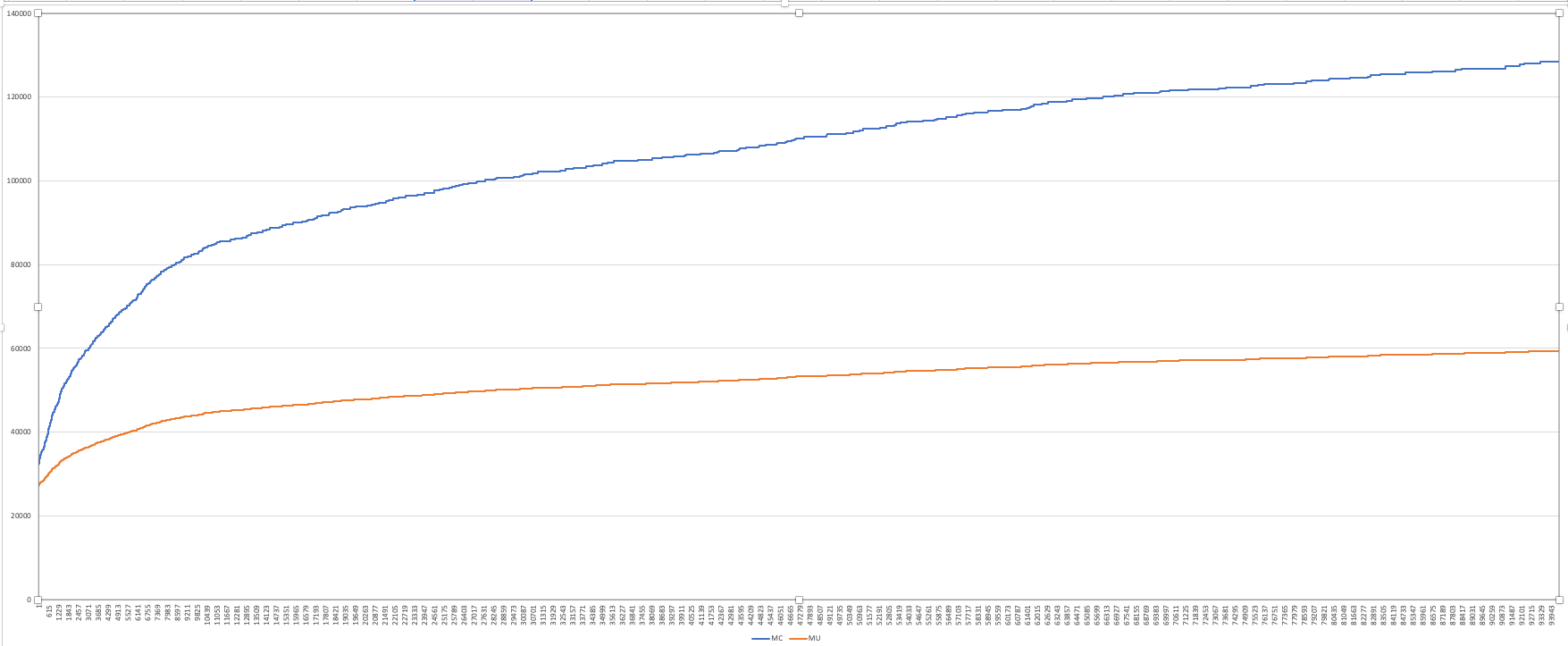
小结
- 基本上成功复现线上问题,但确实没有线上观察到的内存增长那么快
- 因为整个复现过程比较漫长,所以没做更多的实验,不好判断各个参数对metaspace的影响程度
后续
- 因为SGC后续也不再使用,延迟敏感的会上到JDK11用ZGC,延迟不敏感的换回G1
- 等十一节后,差不多又有节点内存飙高了,再抓个现场验证下前文分析的逻辑, 补下图
- 验证下G1在高并发的情况下疯狂调用这个反射的逻辑,会不会出现类似的情况,如果仍然存在,需要继续考虑调参,或者提给社区讨论下这里能不能减少或避免反射。