ABSTRACT
在基于LSMT实现的数据库中,compaction是很重要的机制。compaction虽然有助于维持长期运行过程中的读低延迟,但在compaction过程中读延迟牺牲大。这篇论文中,深度分析了compaction相关的性能损耗,并提出了缓解的技术。我们将大的昂贵的compaction offload到了单独的compaction server,让datastore server更好地利用他自己的资源。此外,因为新compact的数据已经在compaction server的主内存里了,我们通过网络从compaction server把数据抓到datastore server的本地内存,避免读filesystem的性能损耗。事实上,在把workload切换到compaction server之前,预取 compact的数据已经可以消除缓存失效的影响,这时候compaction server只当是远程缓存。因此,我们实现了一个更智能的预热算法确保所有读请求都能被datastore server的本地缓存服务,即使它还在预热。我们已经集成进了hbase,使用YCSB和TPC-C的benchmark显示我们的方法显著消除了compaction相关的性能问题。也展示了compaction server可扩展性。
1. INTRODUCTION
这篇论文的主要贡献:
- 对HBase和Cassandra中compaction的性能分析
- 一个将compaction卸载到一或多个独立的compaction server上的可扩展的解决方案
- 一个将compact后的数据从compaction server的内存中通过网络高效地流向datastore server本地缓存的方案
- 一种智能算法,用compact的数据预热datastore server本地缓存
- 基于HBase的上述功能的实现和分析
2. BACKGROUND
本节概述了对基于 LSMT 的数据存储中的compaction的背景,并简要概述了在 HBase 和 Cassandra 中如何执行compaction。
2.1 LSMT
log-structured merge-tree(LSMT)是一种key-value的数据结构,用来实现高吞吐的数据存储。它是一种混合数据结构,有主内存层(C0),和一或多层的文件系统层(C1或更多)。更新都写进C0,然后批量flush到C1,每次flush生成一个不可变文件,文件内容是有序的key-value对。
介绍了下LSMT的基本结构。他把memstore或者memtable叫做C0,把文件系统中的file叫做C1。有的实现可能存在多层文件系统,可能有C2、C3...
首先对于client,更新操作极快,因为只写内存。第二,flush因为能明显减少磁盘I/O,所以也很高效。对于磁盘来说(HDD),批量顺序写文件比随机写文件更快。这个是该数据结构能够支持高吞吐的原因。第三,对于一个key的多次更新,可能分散在C0和C1的多个文件中。因此一次随机读必须先查C0,然后C1,然后C...,直到找到最新的value。因此文件内容是按key排序的,每个文件会有一个索引用于加速随机读。
介绍写性能高的原因。 介绍读过程要读多处,对结果做合并。
这些只读文件在文件系统中不断生成,会导致读越来越慢。定期地选择两个或多个文件合并成一个文件,可以解决这个问题。合并过程会用最新的value覆盖旧value,并且抛弃已删除的value,从而清理过时的数据。
该过程就是compaction。compaction可以优化读性能。
2.2 HBase
介绍了HBase的数据模型

介绍了HBase的架构,主要是能做到表的弹性和集群的弹性。
HBase用HDFS作为底层文件系统,每个region的每个column family下存储一或多个storefile(就是上面说的C1层不可变文件)。通常一个HBase的region server节点和一个HDFS的datanode部署在一起,用来保证数据的本地化率。
client和HBase的交互方式:支持点读、点写,和带有filter的scan。写请求会先写入memstore(LSMT的C0)。允许每个row的每个column有多个版本的value。每个region每个column family有一个memstore。当memstore的大小达到阙值,会flush到HDFS生成storefile。读操作会扫描memstore和所有可能的storefile。每个region server还维护了一个block cache缓存storefile中的block,用来提高读性能。
当一个region的storefile数量达到限制,region server会执行compaction,把多个storefile合并成一个。当compaction触发,有个特定的算法会选择合并哪些storefile。如果选了了全部storefile,就叫做major compaction,否则是minor compaction。major compaction会清理被标记删除的数据。因此major compaction更昂贵,也通常更耗时。
2.2.1 Exploring Compactions
HBase 中的默认compaction算法使用启发式算法,尝试根据管理员指定的某些约束来选择要compact的storefile的最佳组合。目的是让管理员更大程度地控制compaction的大小,从而间接控制compaction的频率。例如,可以指定每次compaction可以处理的存储storefile数量的最小和最大限制。算法还允许对一次compact的总文件大小进行限制,以便minor compaction不会变得太大。最后,可以指定一个 ratio 参数,以确保compaction中包含的每个 storefile 的大小在平均storefile大小的某个因子内。该算法会寻找满足所有这些要求的排列组合,并选择最好的一个(或没有),优化比率参数。我们可以配置 HBase 以在高峰时段和低峰时段使用不同的ratio参数。
#TODO 搞明白这个ratio的逻辑
2.3 Cassandra
Cassandra是另一个流行的分布式KV数据库。它的设计融合了Bitgtable和Dynamo的元素。和HBase有很多相同点,也在一些重要的方面有区别。
Cassandra是无中心的架构,client可以发送请求给集群中任意节点, 然后再被转发给正确节点。Cassandra也允许应用选择一致性级别,选择最终一致,可以提高性能。选择和HBase一样的强一致,会牺牲性能。为了快速访问热数据文件,HBase维护了自己的block cache,Cassandra依赖OS cache,还可以使用更细粒度的行级缓存。最后Cassandra使用了和HBase略有不同的compaction算法(Section 8的tired compaction)。Cassandra的minor compaction也会清理被删除的数据。Cassandra也可以限制compaction速度。
但Cassandra和HBase还是有两个重要的相似点:
- Cassandra也会将数据分区,每个分区单独跑compaction
- Cassandra也会flush内存中的更新,有序批量的写入只读文件 虽然我们是在HBase上实现的,但这些相似点让我们相信,该方法同样适用于Cassandra和其他基于LSMT的数据库。
HBase是存算分离架构,offload掉compaction很容易。但Cassandra存算一体,如果要offload掉compaction,难道要把compact前后的数据都通过网络IO与compaction server交互吗?
3. ARCHITECTURE
我们的方案在架构上增加了两个组件:
- 一个中心化的compaction manager
- 一堆compaction server
与HBase的集成架构如图Figure 2
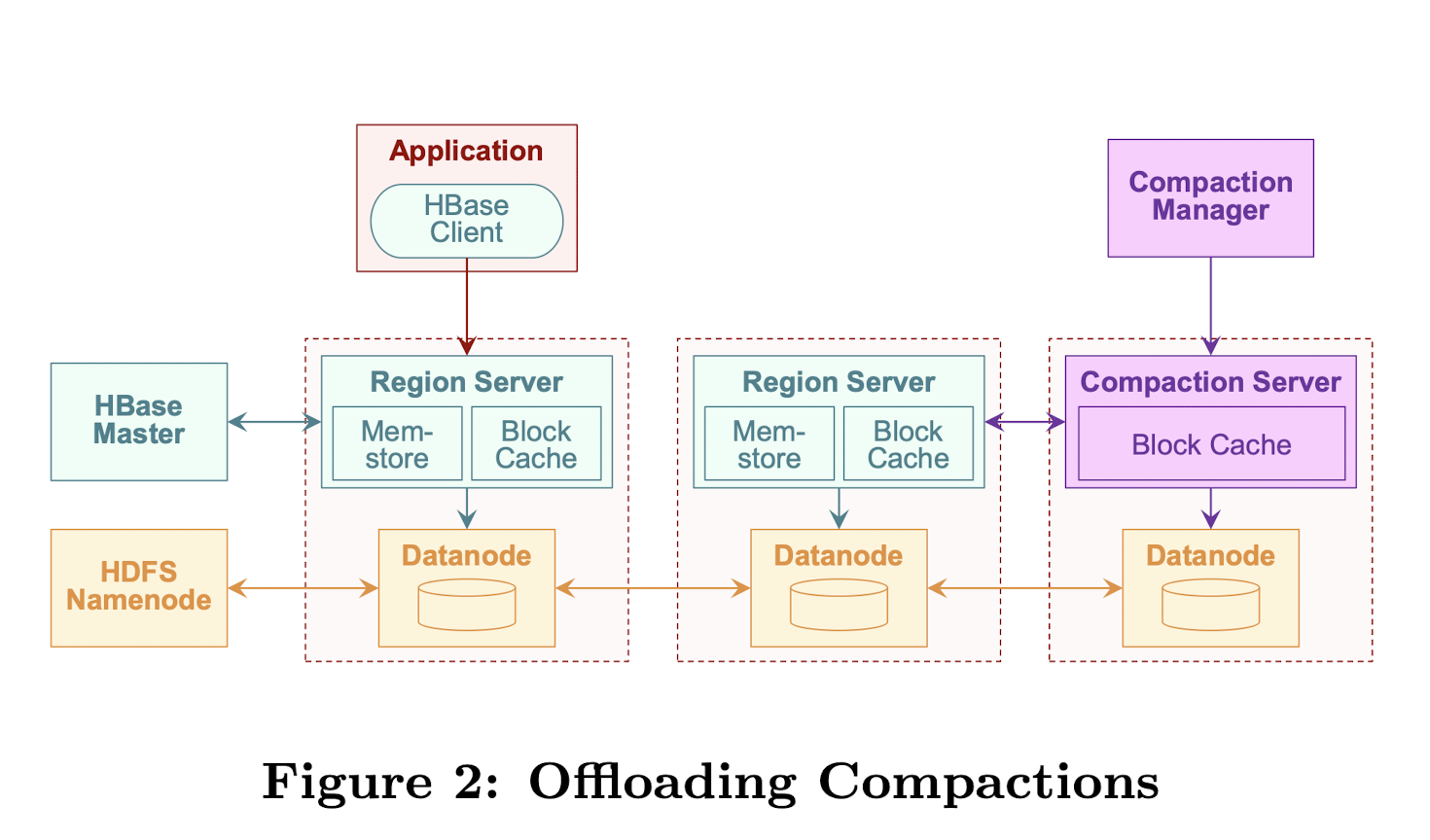
compaction server像region server一样执行compact。同样是从HDFS读需要compact的文件,将compact后的文件写回HDFS。
compaction server可以弹性扩缩容。每个compaction server负责一部分region的compaction。compaction manager负责将region分配给compaction server,就像HBase master负责将region分配给region server一样。
虽然实现上对HBase的代码做了大量修改,但我们实现上尝试用模块化的方式来做。我们使用HBase master和region server的代码作为基础来实现compaction manager和compaction server。例如把compaction算法作为黑盒,compaction server复用了从HDFS读取storefile和执行compact的代码。然而也需要修改特定的region server子模块,能够让region server将compaction卸载到compaction server,并且通过网络接收compact后的数据来做高效的预热。
4. EXPERIMENTAL SETUP
本节介绍实验环境。
4.1 Environment
我们在一个由20台Linux机器组成的同构集群上运行了实验。每个节点都有一个 2.66 GHz 双核英特尔酷睿 2 处理器、8 GB RAM 和一个 160 GB 的 7200 RPM SATA 硬盘。节点通过千兆以太网交换机连接。操作系统是 64 位 Ubuntu Linux,Java 环境是 64 位 Oracle JDK 7。我们使用了低级软件版本:HBase 0.96,HDFS 2.3,Cassandra 2.0和YCSB 0.1.4。
4.2 Datastores
4.2.1 HBase/HDFS
HBase master、HDFS namenode和Zookeeper部署在一个节点上。为了更好的了解compaction的性能损耗,我们修改了HBase少量关键配置。
- compaction文件选择率从1.2调整到3.0
- region server设置使用7G内存,其中6G用于block cache
- 选择Snappy做压缩算法 在所有的实验中,每个region server和compaction server都有各自的datanode,集群中只有3个datanode。
4.2.2 Cassandra
因为Cassandra使用OS cache,我们只为它配置4G内存,并且不启用row cache。我们使用了ByteOrderedPartitioner,能更好的用主键来做顺序scan操作。
ByteOrderedPartitioner应该是一种顺序分区的功能。看样子Cassandra支持多种分区方式。
4.3 Benchmarks
典型的 OLTP 工作负载会生成大量并发执行的读写事务。大多数事务执行较小的读和更新,但少数可能执行较大的范围扫描或全表扫描。在我们的实验中,我们尝试使用两个基准测试来模拟这些工作负载特征。
使用YCSB来做HBase和Cassandra的更新密集型workload的压测。我们启动不同的client进程分别进行读和写。写workload就是100%的更新,读workload有90%的gets和10%的scan。使用Zipfian分布来更接近一个OLTP workload。
TPC-C是一个著名的OLTP基准测试,我们用了TPC-C的实现PyTPCC,可以用于多种云数据库,包括HBase。因为HBase不支持事务,所以基准测试简化了事务执行,不保证ACID。
5. OFFLOADING COMPACTION
OLTP应用的一个关键性能指标是在高吞吐下的低响应时间。这一节,我们首先展示在一次大compaction执行期间和刚执行完的时候,读性能显著受损。然后提出和评论一些缓解策略。
5.1 Motivation
为了明白HBase compaction对读性能的影响,我们运行10个读线程访问1个region server(没有compaction server)。测试表有1个region,3百万行,大约4GB未压缩数据。这能确保数据集能放进region server的6GB block cache。5秒一次记录get和scan的响应时间。
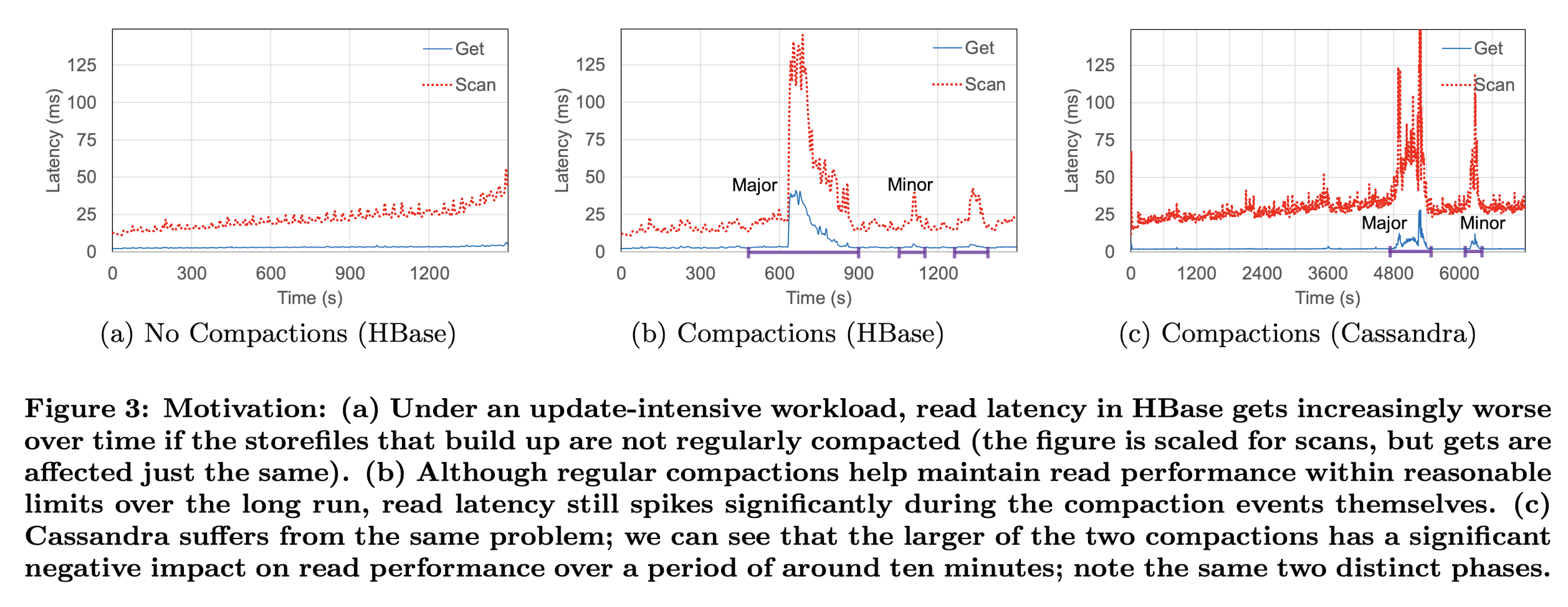
Figure3展示了在每个实验中get和scan的响应时间。Figure3(a)观测到,在完全关闭compaction的情况下,读性能随时间推移逐步下降。Figure3(b)显示,虽然compaction有助于保证读性能在合理范围内,但每次compaction都会引发响应时间显著增长。也能看出major compaction比minor compaction对读性能影响更大时间更长。注意,get和scan都会被major compaction影响。Figure3(c)显示,Cassandra也是同样的现象。
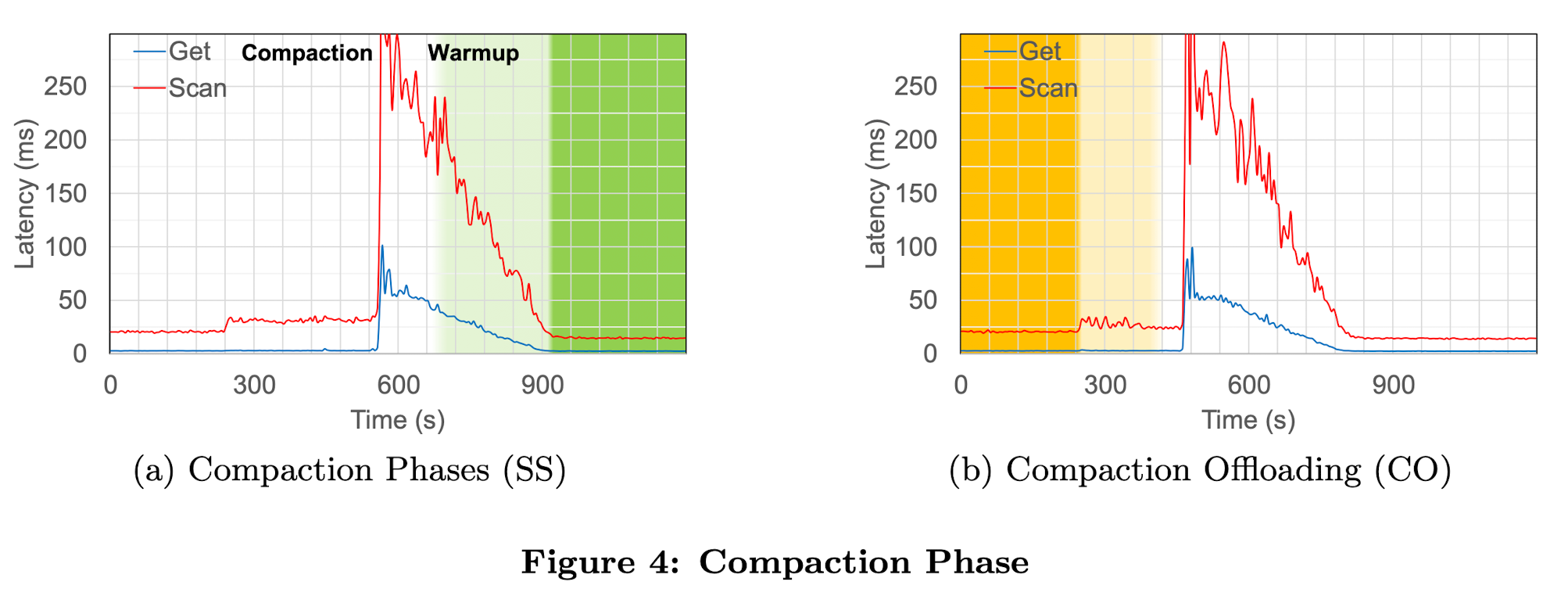
Fugure4(a)中展示了compaction的两个阶段对读性能的影响。
- compaction:执行过程中需要消耗CPU,自然影响读性能。
- warmup:compaction执行结束之后,之前block cache中缓存的数据失效,需要重新加载compact后的文件并缓存。 这两个原因导致读响应时间在长时间内严重受损。
warmup阶段要经历缓存命中率从0到100%的过程。
5.2 Compaction Phase
我们先尝试分析compaction阶段的性能损耗。观察表明,在datastore server高负载的情况下,compaction阶段的性能下降可能会更明显。换句话说,使已经饱和的处理器过载会导致响应时间激增,并且compaction本身需要更长的时间才能完成。对datastore server来说,一个管理这种负载的方法是限制compaction资源消耗。通过限制compaction速度,datastore server可以在更长的时间内摊销其成本。事实上,这也是Cassandra采用的方法,它限制compaction吞吐为一个可配置项(默认16MB/s)。然而,这个方法也没有彻底解决这个问题,主要有3个理由。
- Figure 3(a)显示,即使限速,compaction时的响应时间仍然有激增
- 如果限速更严格,用更长的时间去消化性能损耗,那么compaction花费的时间越长,在这期间就有越多的过期数据需要维护,这也会影响读性能
- 即使限速可以缓解一些性能损耗,但它对随后的warmup阶段没有用 ![[阅读/20221018-Compaction management in distributed key-value datastores/figure4.png]]
因此,我们的方法将昂贵的compaction卸载到了单独的compaction server上,让region server可以使用全部资源处理真正的应用程序的workload。该方法有两个明显的收益:
- 避免了region server用于compaction的CPU损耗
- compaction可以更快执行,因为它运行在独立的server上 尽管compaction需要从文件系统读storefile,而不是内存(region server是可以从它的block cache里读的),但我们在实验中没有观察到任何负面影响。我们用YCSB评估卸载compaction的优势。我们简单添加了compaction manager和一个compaction server,Figure4(b)展示了get和scan的响应时间。对比Figure4(b)和正常模式的Figure4(a),可以看出有独立的compaction server时,compaction阶段更短,读延迟也明显优化。另一方面,也能看到在compaction完成之后,长时间的warmup阶段,读性能没有提升。因此,接下来我们讨论使用compaction server主内存中compcat后的数据来优化warmup阶段的优势。
执行compaction要占用CPU,则会影响正常读性能。一般解决方法是限制compaction速度。但会拉长compaction执行时间。 offload compaction之后,不需要做限速,自然compaction执行更快,从头论文提供的图来看,读性能没明显改善。而且warmup阶段的读性能下降仍然存在。 之后就是讨论如何优化warmup阶段。
5.2 Warmup Phase
如之前的讨论,我们发现一旦compaction完成,region server必须将新compact的storefile从磁盘读到block cache。在这个阶段,会因为block cache的缓存命中率低,导致读性能受损严重。实验结果表明,这对我们的workload有很明显的负面影响。事实上,我们往往会看到一个延长的阶段,长达几分钟的响应时间严重降级,无论是单个get还是scan。因此,在本节的其余部分中,我们将分析此特定性能问题并尝试缓解它。
5.3.1 Write-Through Caching
首先,我们分析标准模式的warmup阶段。我们考虑在write-through模式下,是否缓存compaction的输出,即每个block写入HDFS的同时也缓存到block cache。理想情况下,可以完全消除warmup阶段。然而我们实验表明,这种方法并没有产生有希望的结果。为了测试这个想法,我们修改了HBase允许在write-though模式下缓存compact之后的block。figure5(b)我们使用的该方法,对比标准模式的figure5(a)。我们看到虽然warmup阶段有一定改善,但性能下降传递回了compaction阶段。进一步分析后发现,在compaction期间有大规模的热block被逐出block cache,导致读性能下降。换句话说,在compaction期间,新compact的完成的数据竞争region server有限的block cache,可能将仍需读的数据逐出内存,然而只有在compaction完成之后,才会切换到读新数据。因此,这个方法只是将问题转移到了compaction阶段。
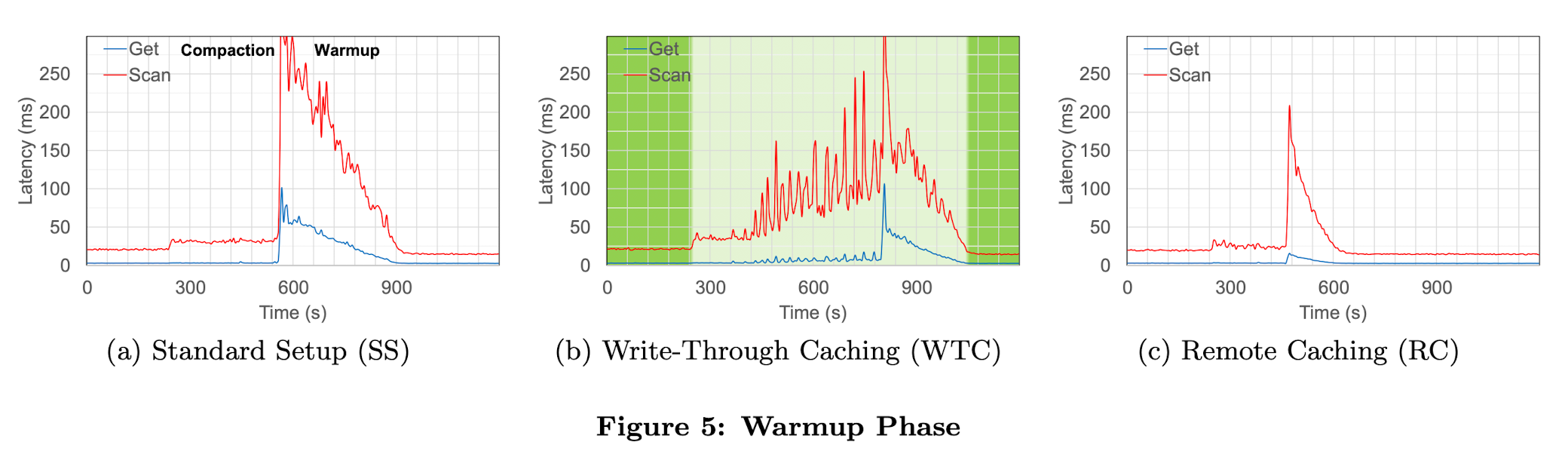
offload compaction优化了compaction阶段的性能影响,然后开始优化warmup阶段。 warmup阶段的问题根源是,compaction之后大量缓存失效,重新加载影响读性能。首先想到的是在compact过程中,写HDFS时将block直接缓存到block cache。 但发现,有限的block cache既要存储当前正在使用的block,还要存储compact后的新block,而compact后的新block不会立刻使用,要等整个compacion完成才能使用。这过程中,自然也会导致缓存命中率降低,读性能下降。
显然,region server的主内存越大,就有越多的当前数据和compact后的数据同时放进主内存,就有更少的缓存抖动。然而,这会预留大量内存,多余的内存只有在compaction时才会用到。基于这个理由,我们相信使用少量的compaction server做远程缓存,让region server共享,可以用更少的资源解决这个问题。
每个region server预留更多的内存,更大的block cache自然能缓解这个问题,但又有明显的资源浪费。 随后提出使用compaction server做远程缓存,可以让所有region server共享,则可以用更少的资源缓解这个问题。
5.3.2 Remote Caching
compaction offload之后,可以利用compaction server上的write-through缓存,从而将这两种方法结合起来。作为独立的节点,compaction server可以在warmup阶段作为远程缓存,因为它早已经将compaction输出的数据缓存在主内存中了。使用这个方法,region server读最新compact的数据,可以请求compaction server的内存,而不是读磁盘。在磁盘和网络 I/O 之间有一个明显的权衡。由于我们的主要目标是优化响应时间,网络 I/O 比磁盘 I/O 更快,这种权衡是值得的。
我们已经实现了一个RPC允许region server从compaction server读取缓存的block而不是HDFS的datanode。为了降低网络传输开销,我们在compaction server使用Snappy压缩了block,在region server接收到之后再解压。这会带来轻微开销,但能节省总的传输时间和网络I/O,是一个可接受的权衡。figure5(c)使用了该方法,在warmup阶段的响应时间有显著优化。虽然仍然会有过时的block被逐出内存导致缓存未命中,但是warmup阶段完成的更快,因为读compaction server内存比读磁盘更快。当然,compaction offload的优点依然能保留下来。
不过仍然能观察到,因为缓存未命中,compaction阶段和warmup阶段存在明显的性能差距。因此,虽然远程缓存比从本地磁盘读取提供了显着的改进,但由于这些缓存未命中而导致的性能损失仍有待解决。
compaction offload解决了compaction阶段的性能损耗。 write-through缓解了warmup阶段的性能损耗,但有俩问题:
- 要冗余内存,浪费资源
- 反而因为竞争缓存空间,会影响compaction阶段性能 结合这两个方法:使用compaction server做远程缓存,在保证compaction阶段性能不受影响的同时,极大优化了warmup阶段的性能。
5.4 Smart Warmup
为了实现进一步的优化,我们通过事先读取并缓存compacted后的数据,从根本上避免缓存不命中。我们讨论两种选项。
5.4.1 Pre-Switch Warmup
在第一个选项中,我们在切换到compacted后的数据之前,预热本地缓存(从compaction server传输到region server)。这很像我们之前讨论的write-through缓存的方案。也就是说,它的有效性取决于主内存的富余程度,以便于region server可以同时缓存当前block和compacted后的block,从而实现无缝切换。与write-through缓存(在compaction期间进行预热)相比,我们在compaction完成后执行预热。compaction在远程执行,并且通过网络读取compacted后的数据,所以region server的compaction阶段性能不受影响,warmup也能更有效率。
先理解下 switch:compaction完成之后,读数据要切换到新的storefile。 warmup:切换后,新的storefile没有缓存,逐渐加载进block cache的过程是warmup。 write-through cache:在没有compaction offload的情况下,compact过程中,将产生的新block直接放进block cache。但因为内存有限,在compaction阶段就会产生内存竞争。 pre-switch warmup:使用compaction server做远程缓存之后,compact完成之后,从compaction server读新数据到region server的block cache。好处是不影响compaction阶段,从网络读也更快。
figure6(a)展示了这个方法的性能。pre-switch warmup包含两个子阶段,分别在图中用灰色和粉色表示。回忆一下,我们有6G内存用于block cache。因为当前数据只使用大约4G,pre-switch warmup可以在不对性能产生严重影响的情况下使用剩余的2G(图中gray部分)。然而,随着warmup持续进行(达到pink区域),compacted后的数据和当前数据都在内存中,造成严重的内存竞争。这也会影响切换后的性能(orange部分),因为必须重新读取那些被当前数据覆盖掉的compacted后的数据。因此,pre-switch warmup阶段花费的时间越长,这种方法的效果就越差。尽管如此,它的整体性能仍然优于没有compaction server的write-through 缓存方法(figure5(b)),因为在后一种情况下,一旦block cache填满,新旧数据已经在压缩阶段开始竞争; 然而,对于远程缓存,有害的缓存变动仅在pre-switch warmup阶段的较短部分发生。
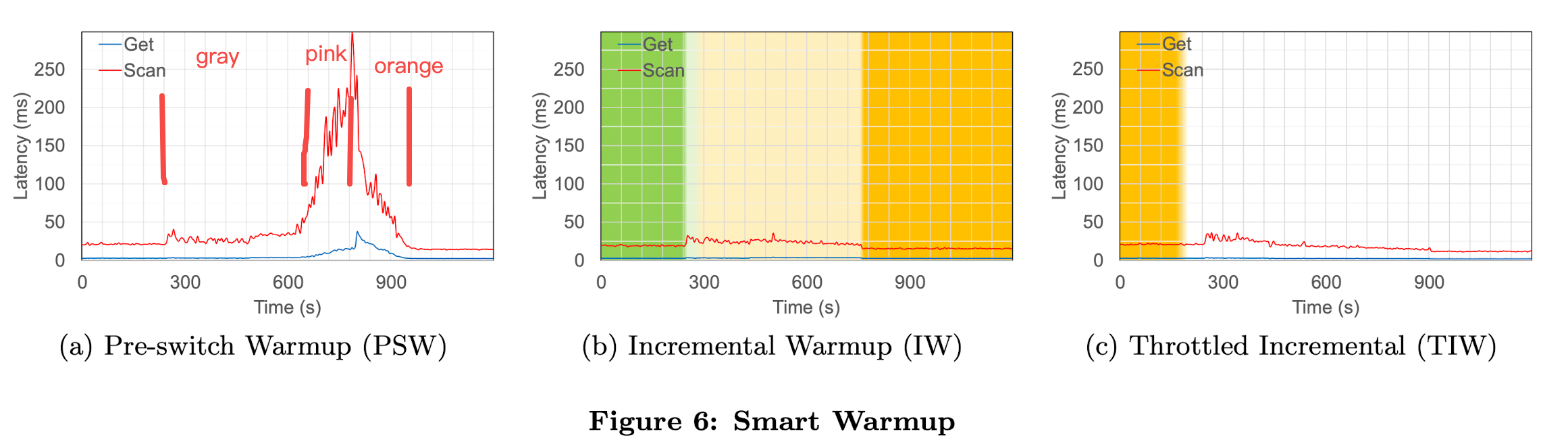
pre-switch warmup分为了3个阶段,图中没有标颜色,我按理解标了一下: gray:在block cache有富余内存(2G)时,从远程缓存warmup,对性能影响不大 pink:block cache不足时,出现新旧数据的内存竞争,影响性能 orange:switch之后,因为加载的新数据又可能被逐出内存了,又重新加载,所以性能需要时间逐渐恢复。 整体上比write-through cache方法要好,起码不会影响compaction阶段性能。
由于 OLTP 工作负载通常会存在热点,因此我们还尝试了此方法的一个版本,在该版本中,我们仅使用与当前数据(灰色)并排的热数据来预热缓存,这样我们就不会导致任何缓存抖动(粉红色)。然而,这种策略在测试时似乎没有提供额外的好处。我们意识到这是因为热数据只占blocks的不到 1%,在任何一种情况下(切换之前或之后)都可以轻松立即获取,这意味着 99% 的缓存未命中实际上与冷数据相关联。
单独对1%热点数据的情况做了测试。因为热数据只有1%,没有缓存竞争。 然而加载1%的数据,在任何情况下都很快,也就没有太大意义。
5.4.2 Incremental Warmup
我们以上的实验分析表明,region server富余内存越少,pre-switch warmup性能表现越差。因此,我们提出一种incremental warmup策略来解决这个问题,并且不需要富余内存。要满足两个前提。第一个方面是我们顺序地从远程缓存中获取compacted的数据,其中每个block替换本地缓存中相应范围的当前数据。为此,我们依赖 LSMT 写入的storefile按key预排序。也就是说,按key顺序传输compacted后的block,新compacted的block替换同样key范围的当前block。在任何给定时间,我们维护incremental warmup阈值 T,它表示具有以下属性的行键:所有row key小于或等于 T 的新block都已被获取且缓存,相应地,所有row key小于等于 T 的旧block都已从本地缓存中逐出。这意味着row key大于 T 的所有旧block尚未被逐出,并且仍在region server的缓存中。
读操作按如下规则执行。对于请求 R 这个row key的get请求,或者以 R 为start key的scan,如果 R ≤ T ,我们直接读新compacted的storefile,否则就读旧的。按这个方法,我们确保所有请求都能立即使用region server的block cache,因此消除了缓存未命中的影响。如figure6(b)显示,该方法的提升效果非常显著。
一个get请求只读一个row,但scan却跨多个row甚至多个storefile的block。因此scan请求会遇到以下三种情况。如果start的start和end row都在T以内,它将只读已经缓存的compacted的数据。如果scan的start row比T小,但end row比T大,它仍然读compacted的数据,虽然需要读的数据还没全部被缓存,但随着scan进行,compacted的数据也在并行地流入region server,因此scan会尽可能地读到缓存的数据,当要读的key超过当前的T,才会因为没命中缓存而降级。如果scan的start和end key都超过T,它将读当前的block,尽可能地命中缓存。如果T中途超越scan的key,将会驱逐要读的block,才会碰到缓存未命中。然而,因为scan读本地缓存的数据,比从远程缓存读数据要快,所以我们没有观察到这样的情况经常发生。事实上,我们在实验中看到的缓存未命中相对较少。实验中,在所有情况下,任何读请求要么完全由compacted数据提供,要么完全由当前数据提供。
作为最后的改进,我们warmup阶段做了限速。结果如图fiture6(c)所示。这实质上意味着 T 的前进速度比没有限速时慢,因此,warmup阶段持续时间更长了。但是,结果是,此阶段的性能开销几乎被消除了。它降低了数据传输的 CPU 成本,并减少了由于当前的block被新数据覆盖过快而导致缓存未命中的可能性。因此,我们看到compact和warmup阶段几乎没有留下任何明显的影响。
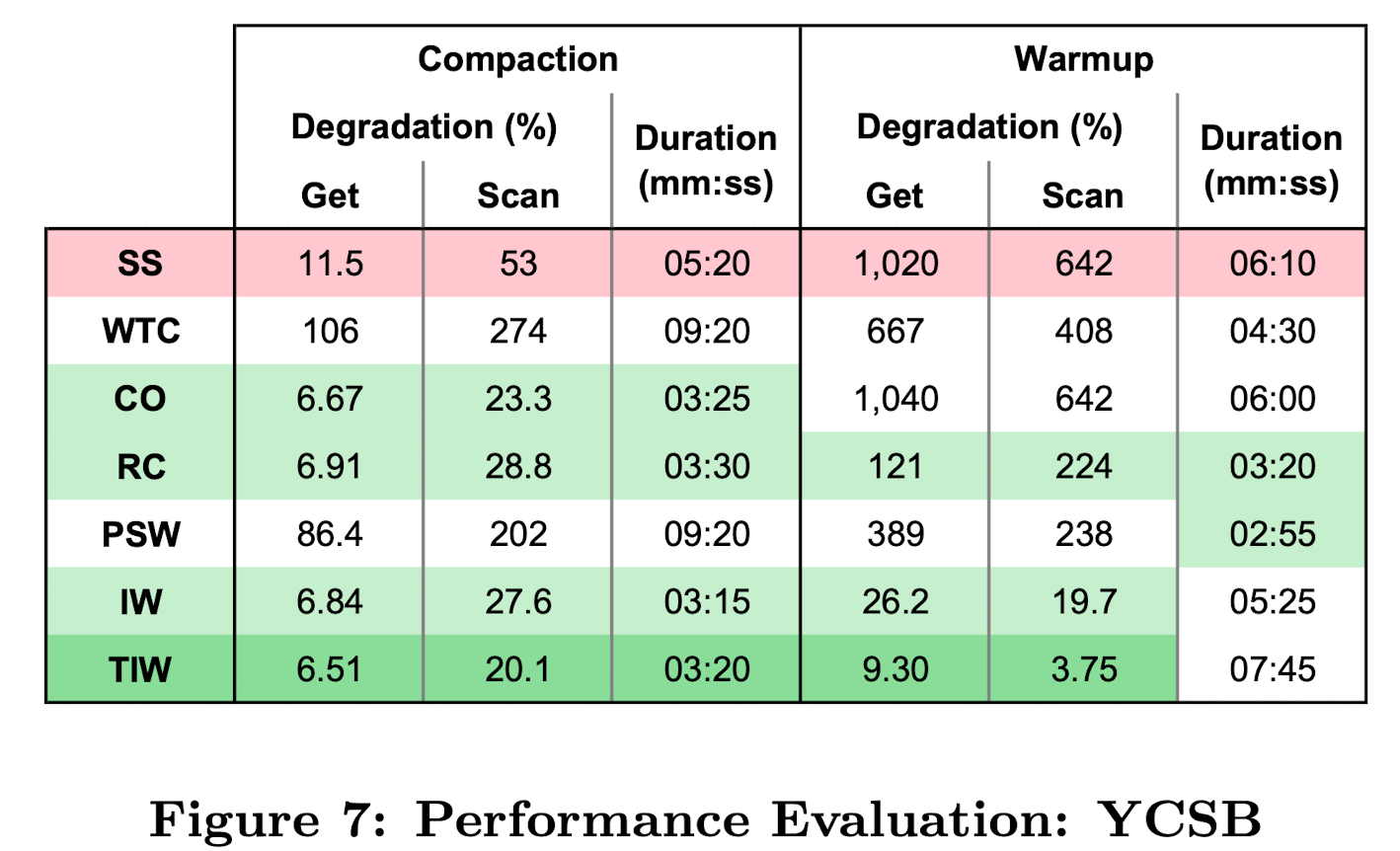
我们的 YCSB 测试总结在figure 7 中。对于每种方法,我们分别显示了压缩和warmup阶段读取延迟的下降,用compact开始前的平均延迟作为基线来比较。重要的改进以绿色突出显示。我们可以看到,使用我们最好的方法,限流incremental warmup(TIW),get的性能下降到只有7%/9%(compacted/warmup),而scan的性能下降到只有20%/4%。compact阶段的持续时间也大大缩短。虽然warmup阶段比简单的远程缓存 (RC) 长,但 TIW 显著优越的性能弥补了这一点!
5.5 TPC-C

又在TPC-C的benchmark上做了性能测试,同样平均响应时间降低很大。
6. SCALABILITY
通过使用compaction manager来监督所有compaction sever上compaction的执行,我们可以像扩展region server一样扩展compaction server。事实上,由于 HBase 将其数据分成region,因此我们可以方便地使用相同的分区方案来实现我们的目的。因此,我们的分布式设计继承了HBase的弹性和负载分布特性。
6.1 Elasticity
对于随时间波动的应用workload,HBase提供了按需增删region server的能力。同样,compaction manager可以同时管理多个compaction server。它同样基于Zookeeper管理region与compaction server之间映射的元信息。
6.2 Load Distribution
随着数据集的增长,HBase会创建新的region并分布到region server上。我们的compaction manager能自动探测这些新region并且分配到可用的compaction server上。我们继承了HBase的模块化设计,允许我们根据需要使用自定义的负载均衡算法。我们当前使用的是一个简单的round-bobin策略。我们可以设想更复杂的算法,根据compaction server当前 CPU 和内存负载动态平衡region。
6.3 Compaction Scheduling
调度compaction是个有意思的问题。当前,我们让region server调度它自己的compaction。然而,我们的设计是让compaction manager基于compaction server的动态全局视角来执行compaction调度。
一个重要的参数是一个compaction server当前可以执行多少compaction。因为我们用compaction server的主内存做远程缓存,所以当前正在compact的数据量总和不能超过它的内存。该限制的粗略估计可以计算如下。
给一个compaction server读且compact的预估速率c (in bytes/s),一个region server通过网络将compact后的数据取回的速率w (in bytes/s),处理b (in bytes)大小的数据,可以计算出时间 D (in seconds): D(b) = b/c + b/w。然而,一个有m bytes主内存的compaction server可以同时处理l个平均大小为b的compaction, l = ⌊m/b⌋。因此,平均一个region t seconds有b bytes的数据需要compact,那一个compaction server最多可以负担的region数是h = t/D(b) ∗ ⌊m/b⌋。因此给定一个工作负载:每个region每t seconds触发T次compaction,我们就可以给每个compaction server分配⌊h/T ⌋ 个regions 。我们对于R个region的数据集,就需要给出 C = ⌈R/ ⌊h/T ⌋⌉ 个compaction server。例如对于以下的参数,c=20MB/s,w=8MB/s,m=6GB,b=4GB, T=1/hour,and R=10regions,得出需要C=2 个compaction servers。
6.4 Performance Evaluation
我们将5台region server增加到10台,使用YCSB来测试方案的扩展性。5个region server节点的部署,5个region,1000万row数据,配1台compaction server。启动两个client,分别有40读线程2写线程。10个region server的部署配置2倍的负载:2000万row数据,10个region,4个client。起初只配置一台compaction server,使其过载。接下来,我们使用两个compaction server运行了相同的实验,以展示我们的架构有效地在两个server之间分配负载的能力。实验运行了四个小时;在此期间触发了多个major compaction。

Figures 9(a) 和 9(d) 展示了实验结果。Figures 9(a) 展示标准模式部署,没有compaction server,5台region server情况下的平均响应时间,可以看到有明显的延迟尖刺。Figures 9(d) 展示的是5台region server配1台compaction server,可以处理由5台region server触发的compaction,消除标准模式下的延迟尖刺。Figure 9(c) 中,10个region server配1个compaction server,在这个case中compaction server已经过载。1个compaction server有6G主内存,只能同时处理1个region 4G的数据,无法并行执行多个compaction。因此compaction执行推迟,region server的读性能越来越差,因为store file被创建的越来越多,block cache空间不足。最后,我们可以在Figure 9(d)中观察到,使用两个compaction server,我们可以轻松处理10个region server的compaction负载,并且响应时间在整个执行过程中保持平稳。
7. FAULT-TOLERANCE
我们的方法为卸载compaction提供了高效的解决方案,即使某些组件异常,也能确保其正确执行。本节讨论了几个重要的故障情况,并讨论了我们解决方案的容错性。
7.1 Compaction Server Failure
当compaction manager探测到一个compaction server失败后,会重新分配它的region给其他可用的compaction server。一个compaction server失败的时候会处于这三种状态之一:空闲,正在compact一些region,正在传送数据回region server。如果正在执行一个compaction,它的失败会导致region server收到一个远程异常,然后终止compaction。注意不会有有数据丢失,因为compaction server写的是临时文件,region server也不会去读未compact完的文件。region server会重试这个compaction,分配给其他compaction server。如果没有compaction server可用,region server会自己执行compaction。
如果compaction server失败的时候正在传输compact后的文件回region server,region server也会收到远程异常。在incremental warmup的情况下,有些请求可能已经读到了部分传输过来的数据。因此region server最终去HDFS上去读compact后的store file。因为compaction server在传输数据前已经写完了store file。然而因为剩余的数据需要从HDFS上读取,在预热阶段的剩余时间内,读性能可能会下降。
7.2 Compaction Manager Failure
在我们当前的实现中,为了卸载compaction,region server必须通过compaction manager才能转发compaction server。因此,compaction manager在我们的部署中会出现单点故障。但是,这只是一个实现问题。由于我们使用 ZooKeeper 来维护compaction server的region分配,因此我们的设计为region server提供了一种直接与compaction server通信的可靠方法。
与HBase Master一样,如果compaction manager失败,将不能增删compaction server,因此需要尽快重新启动。但是,正在进行的compaction不受影响,因为region server和compaction server一旦连接就直接通信。
用ZK分配region的实现应该是参考老版HBase的实现,现在都是ProcedureV2了。
7.3 Region Server Failure
如果一个region server在等待compaction返回的过程中宕机,compaction server会根据超时发现连接断开,然后中断compaction。Master会重新分配受影响的region到其他region server,然后重新发起compaction请求。如果region server在incremental warmup阶段宕机,新的region server必须保证只会从HDFS加载新的compact后的store file,旧的store file要同时丢弃。尽管我们目前不处理此故障情况,但我们打算用一个简单的方法,在启动incremental warmup阶段之前修改文件名。这样,如果该region被另一个region server重新open,它可以检测该region的HDFS目录中的哪些文件由于被较新的compact文件取代而被丢弃。
8. RELATED WORK
在过去十年中,可扩展KV存储以及提供更复杂的数据模型和事务一致性的更高级数据存储的数量增长非常迅速。部分数据存储服务为了满足高写入吞吐的需求,都依赖创建多value或多版本,而不是就地更新(in-place)。然而读性能就会受损。因此,compaction是这些数据存储服务的基本功能,有助于定期清理过期的版本,从而将读取性能保持在可接受的水平。
存在各种类型的compaction算法。为了使compaction更有效率,这些算法通常试图通过选择文件避免旧数据重复compact。例如,tiered compaction首先由Bigtable使用,也被Cassandra采用。该算法不是随机选择一组store file进行压缩,而是一次只选择固定数量(通常为4个)、大小大致相同的store file。这种机制的其中一个效果是越大的store file被compact的频率越低,以此降低整体的I/O吞吐。leveled compactions算法由Level DB使用,现在也被Cassandra实现了。此算法的目的是避免读请求要搜索多个store file的需要。该算法实现的方式比较简单,就是通过防止更新值最初就分散到多个store file中。leveled compactions的整体I/O负载显著高于标准压缩,但是压缩本身很小且快速,因此随着时间的推移,对运行时性能的干扰往往要小得多。另一方面,如果集群I/O负载已经很高,或者工作负载是更新密集型(例如时序),那么leveled compaction将变得无效。striped compaction是leveled compaction的一种变体,已经在HBase中进行了原型设计,作为其当前算法的改进。bLSM中实现了另一种变体,它提供了一种解决方案,通过动态平衡现有数据的compaction速率与传入更新的速率,将compaction成本完全摊销到工作负载中。在我们的方法中,我们将compaction方法本身视为黑盒。事实上,除了incremental warm-up方法之外,其他方法根本不关心store file的实际内容是什么。incremental warm-up方法需要按row排序,但也独立于压缩算法。
与 LSMT 一样执行定期数据维护操作的其他数据结构包括 R- trees和differential files 。与 LSMT 数据存储一样,更新最初写入某个短期存储层,随后通过定期合并操作整合到底层长期存储层中,从而弥合 OLTP 和 OLAP 功能之间的差距。SAP HANA 是属于此类别的主要内存数据库。HANA 中的合并是完全在内存中执行的资源密集型操作。因此,服务器必须有足够的内存来同时保存当前数据和压缩数据。原则上,我们的增量预热算法提供与完全内存中解决方案相同的性能优势,同时需要一半的内存。
计算卸载和智能缓存管理都是许多分布式系统中众所周知的技术。但是我们不知道任何其他方法可以考虑卸载压缩,以减轻查询处理服务器增加的 CPU 和内存负载。但是,分离需要处理相同数据的不同任务的概念在基于复制的方法中很普遍。例如,在使用主副本复制的方法中,更新事务仅在主副本上执行,而其他副本是只读的。例如,在Ganymed系统中,各种只读副本用于各种类型的只读查询,而主副本专用于更新事务。本着类似的精神,我们将compaction与事务处理分开,以最大程度地减少这两项任务的干扰。
9. CONCLUSIONS
在这篇论文中,我们为HBase中带来了一种新的compaction方法。我们的目的是为了降低compaction对更新密集型负载中对读性能的负面影响。我们提出把compaction从region server卸载到独立的compaction server上。这允许region server能充分利用机器资源去承担真实工作负载。我们也用compaction server做远程缓存,因为它已经将compact后的数据放在了主内存中。region server通过网络获取数据而不是磁盘。最后,我们提出了一种高效的incremental warmup算法,该算法从region server缓存中的当前数据平滑过渡到从远程缓存获取的compact数据。通过 YCSB 和 TPC-C,我们证明了最后一种方法能够消除所有与compaction相关的性能开销。最后,我们演示了我们的系统可以通过按需扩展compaction server。
对于未来的工作,我们希望使compaction manager更加了解region、region server和compaction server的负载均衡要求。